Intelligent Dossier
AI-powered, multi-tenant company intelligence platform.
AI-Powered Sales Intelligence Built on a Multi-Tenant Node.js Architecture
Express and PostgreSQL backend with explicit concurrency control and asynchronous workers for decision-ready company intelligence.
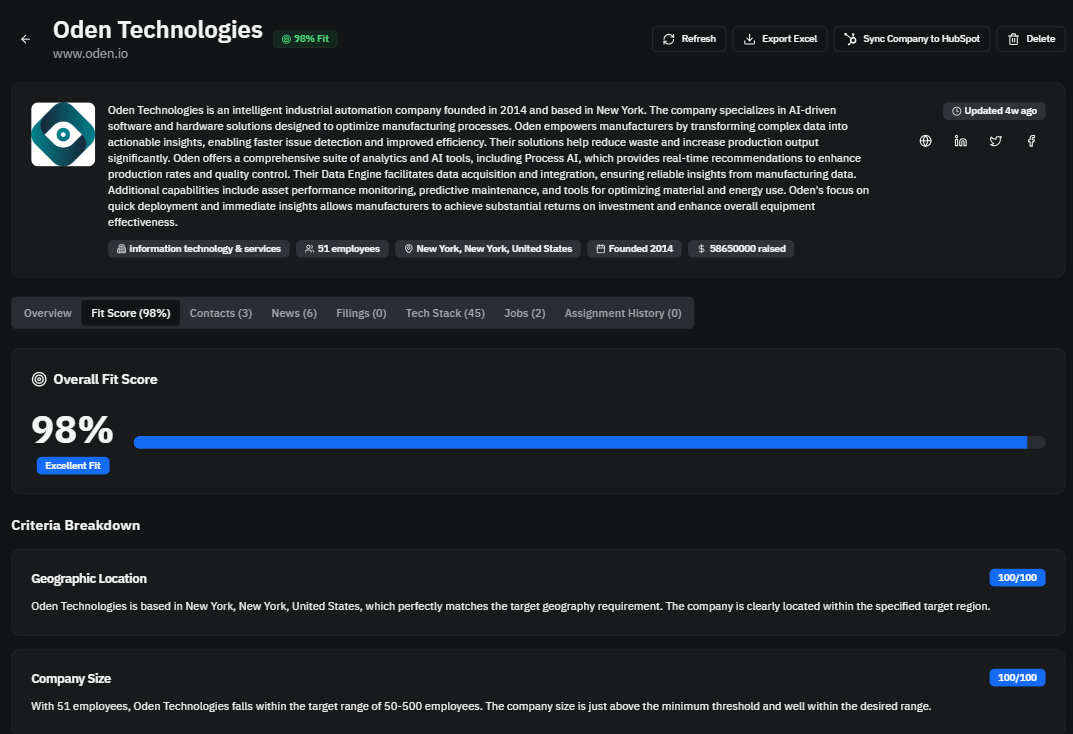
Project Overview
Intelligent Dossier is a multi-tenant SaaS platform that ingests multi-source company data and converts it into structured, AI-assisted sales intelligence. It emphasizes practical backend engineering: Node.js and PostgreSQL performance tuning, Express API orchestration, load-tested workflows, and resilient asynchronous worker pipelines.
The Challenge
Company research data is scattered across incompatible sources and arrives at different cadences. The system needed to unify this data into a consistent model, minimize noise, and remain responsive under concurrent load.
Approach
Built a TypeScript monorepo with shared schema contracts, an Express API layer, and dedicated worker services for asynchronous processing. Added controlled parallelism for heavy endpoints, queue-based database pressure management, and staged relevance filtering (heuristics plus AI) to keep throughput high and costs bounded.
Architecture
Monorepo full-stack with decoupled workers
Major Components
Notable Capabilities
- Multi-tenant org isolation and scoped access
- Asynchronous enrichment orchestration
- HubSpot OAuth lifecycle and data export mapping
- AI-generated company analysis and playbook content
Performance & Reliability Profile
Measured Metrics
| Metric | Before | After | Improvement |
|---|---|---|---|
| Admin Bootstrap Response Time | 90+ seconds | <3 seconds | >=96.7% |
Load Testing
Tool: k6 (load-test.js)
Profiles
- smoke: 5 VUs, short duration validation
- default: ramps to 50 VUs, then spikes to 150 VUs
- spike: ramps to 100 VUs, spikes to 300 VUs
Threshold Targets
- global p95 http_req_duration < 1000ms
- bootstrap p95 < 2000ms
- error rate < 5%
Runtime Controls
- DB pool max connections: 15
- DB queue concurrency: 5
- DB queued query timeout: 30s
- Monitoring worker poll interval: 60s (default)
- HubSpot sync worker includes limiter and retry/backoff support
Key Engineering Decisions
Database Concurrency Control
Introduced a route-level PQueue to cap database operation concurrency at 5 while using a 15-connection PostgreSQL pool, preventing pool exhaustion during high-traffic bursts.
Latency Optimization
Refactored bootstrap-style endpoints to batch and parallelize independent data retrieval with Promise.all, reducing worst-case administrative bootstrap latency from 90+ seconds to under 3 seconds.
Resilience Engineering
Implemented retry/backoff strategies and recovery loops in worker pipelines and third-party integrations (including OAuth token refresh paths and connection reconnection handling).
AI Cost/Signal Management
Applied layered filtering (deduplication, heuristic scoring, relevance screening, ICP screening) before deep AI analysis, improving relevance quality while reducing unnecessary inference work.
Validation & Impact
Methods
- Endpoint-level latency optimization and regression checks
- k6 smoke/default/spike load profiles
- Worker stability validation through retry and reconnection logic
Outcomes
- Major reduction in admin bootstrap latency for high-data dashboard workflows.
- Improved tolerance to concurrent multi-user access via explicit queue/pool coordination.
- More stable background processing through fault-handling and cache lifecycle management.
Project Management
Methodology: Iterative release-driven development
Workflow: Scripted development-to-production promotion with tagged releases
Version Control: Git with release tags (v2.0.0 through v2.2.0 visible in history)
Why This Matters
This project demonstrates senior-level backend ownership: designing for concurrency limits, implementing operational resilience, integrating multiple external systems, and delivering measurable latency improvements in a production-style AI data platform.
- Not just an AI demo: includes real ingestion pipelines, queueing, caching, retries, and CRM integration.
- Shows system-level thinking: throughput, latency, failure handling, and tenant safety were engineered explicitly.
- Combines product impact (decision-ready intelligence) with infrastructure rigor (load testing and operational safeguards).